论文笔记 Data Distillation: Towards Omni-Supervised Learning
Abstract
- Omni-supervised learning: 全方位学习:一种特殊的半监督学习,包括所有可学习的数据和来自Internet的为标记数据
- Data Distillation: 数据蒸馏:一种集成预处理方法,将未标记的数据进行多种变化,使用单一模型自动生成新的训练标记
- 作者主张,目前的视觉识别模型已经具有足够的精度进行自学习(self-learning),从而挑战真实世界的数据
- 实验表面,使用数据蒸馏训练的模型超过完全使用标注数据训练的方法
1. Introduction
Omni-supervised learning,利用所以可利用的训练数据,包括标记和未标记的。
semi-supervised learning,研究主要针对一个完整数据集,将其分为标记和未标记的,然后进行训练,这类研究具有上限,即全部使用标记数据训练。omni-supervised learning 没有上限,只有下限,使用全部数据训练是其下限。
为了解决Omni-supervised learning,本文提出数据蒸馏概念,即使用大量标记数据训练一个模型对未标记数据进行标记,然后使用多出来的数据进行训练。但是使用自己标注的数据进行训练往往没有意义。为了解决这个问题,我们集成单一模型在多种变换上的结果。
self-learning的研究可以追溯到1960s,但是由于近几年监督模型的快速改进,允许我们相信其对于未标记数据的预测,降低了对数据清洗的需要。
为了测试数据蒸馏,我们使用人形骨架检测任务,COCO。训练模型为Mask R-CNN,提升了2个百分点。
2. Related Work
3. Data Distillation
四步:
- 在手工标记数据上训练一个模型
- 将该模型应用于未标记数据的多种变换上
- 将多种预测集成,使预测称为标记
- 联合所有数据再次训练
Multi-transform inference
变换输入来增强精度是一种常见策略,例如:图像裁剪、多尺度等。我们对单一模型使用多种变换推理。
Generating labels on unlabeled data
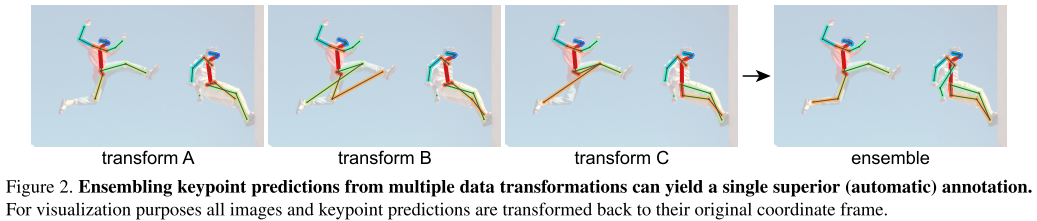
集成多种变换的预测结果经常能获得优于单一模型预测结果。如图2所示。我们发现集成后的预测能产生新的知识,并用于训练模型本身。
例如对于分类问题,可以对一个图片生成平均类别概率向量[^18] ,但是会存在两个问题。1)“soft”标签不能直接用于训练模型,需要修改loss。2)结构化输出的问题,物体检测或姿势估计,平均结果是不合理的。
我们简单的组合这些多变换预测,生成“hard”标签,与手工标记数据中具有相同的结构或类型。生成硬标签需要一些任务特定的逻辑能表征问题结构(例如NMS)。之后即可进行训练。该过程尽管需要推理多次,但是也不训练多个模型更高效。
Knowledge distillation
1)每个minibatch包含手工标记数据和自动标记数据
2)训练schedule需要延长,配合数据量的增加
4. 数据蒸馏用于骨架检测
Data transformations
本文使用几何变换,其能够满足集成预测结果的需求,在集成时需要进行反变换,再集成。本文使用两种常用的变化:尺度变化、水平翻转(数据增强而已)我们对为标记的图片进行缩放,短边从[400,1200],步长100像素。在验证集上应用相同策略,选择一个最优的变换使得模型提升最大,并将该模型作为teacher模型。
Retraining
学生模型在联合数据集上训练,每个minibatch比例为6:4。学生模型可以采用teacher model初始化也可以用ImageNet初始化,我们发现使用ImageNet初始化的效果总是更好,说明teacher 模型进入了局部最优
5. Keypoint检测实验
5.1 数据分割
- co-80: COCO 80K张训练图像
- co-35,2014 val的子集 35k张图
- co-115,上面的组合为:2017 COCO 训练集,115k张图
- un-120,COCO 2017提供了120k张未标记的图片
- s1m-180,从Sports-1M[^19] 随机选择180k个视频,每个视频随机选择1帧
5.2 主要结果
1)co-35作为标记数据,co-80作为未标记数据
2)co-115作为标记数据,分布相似的un-120作为未标记数据
3)co-115作为标记数据,分布不相似的s1m-180作为未标记数据
结果如表1所示
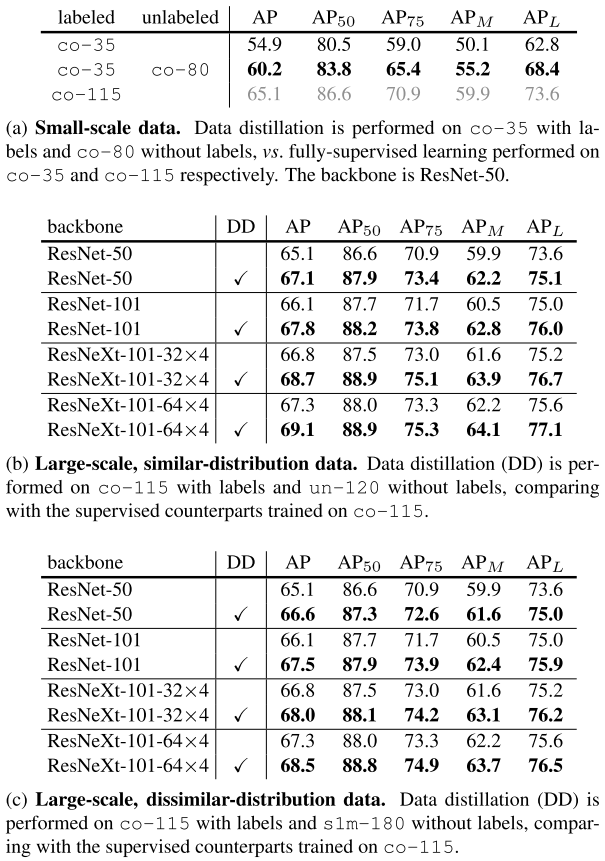
小数据量
这里的实验类似经典的半监督问题策略,即使用一部分标注和完全标注的性能对比,完全标注的结果作为上界。本文提出的方法主要还是用于对实际未标注的数据进行提升更具挑战性。(但是半监督的研究也可以应用于本文的问题,作者为什么没有进行比较?)
大数据量-相似分布
使用co-115和un-120进行训练,使用DD方法进行标注。均匀不同提升。在论文[^27]中使用率1.5倍的全标注数据进行训练AP提升了3个百分点,本文的方法使用DD也提升了2个百分点。
大数据量-不相似分布
使用co-115和s1m-180训练,尽管数据分布不一致,但是AP仍然具有提升,说明DD对数据分布差异具有鲁棒性。
5.3 消融实验
迭代次数
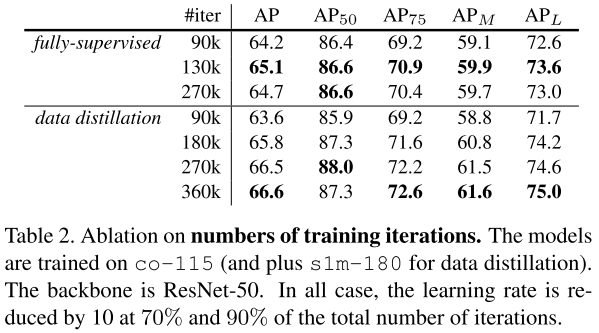
由于数据量增加,因此迭代次数也应该相应增加。为了表面我们的提升不是来自迭代次数的增加,实验结果如表2所示。
对于全监督baseline,130k迭代达到最优,相比默认的90k来说。但是增加到130k时下降,说明过耦合。
另外,DD增加数据量后,360k迭代还未完全耦合。
未标记数据量
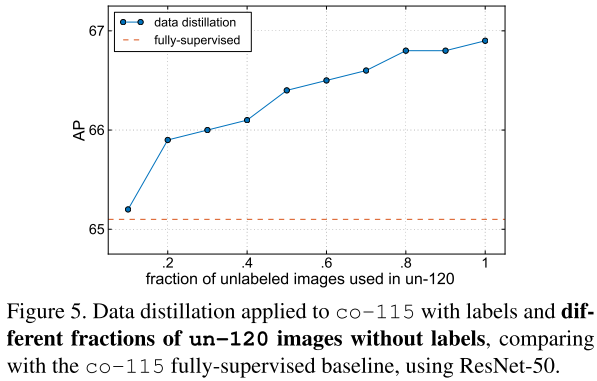
如图5所示,使用不同比例的未标记数据p,minibatch的比例为1:p,迭代次数也相应增加1+p倍(基准次数为130k)。从图5所示,随着数据的增加,AP持续提升。
teacher 模型的影响
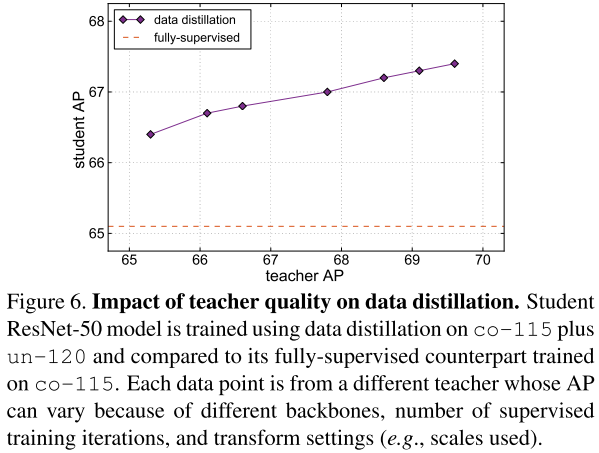
不同的teacher AP的提升,导致student AP的提升
测试时增强

在测试时使用多变换推理也会改进结果。
6. 物体检测实验
6.1 实现
本文选择物体检测器为Faster R-CNN[^30] 使用FPN[^23] 为backbone,并使用RoIAlign改进[^15] 。我们采用如[^31] 中描述的端到端训练。
使用bbox投票[^10] 方法进行组合union训练集。
物体检测涉及多种类别,对每个类别设定得分阈值。我们选择阈值使得未标记图片集中平均每张图片选择的类别数量与标记的数据中每个类别的数量匹配。
图7显示u-120中生成的标记。

6.2 物体检测结果
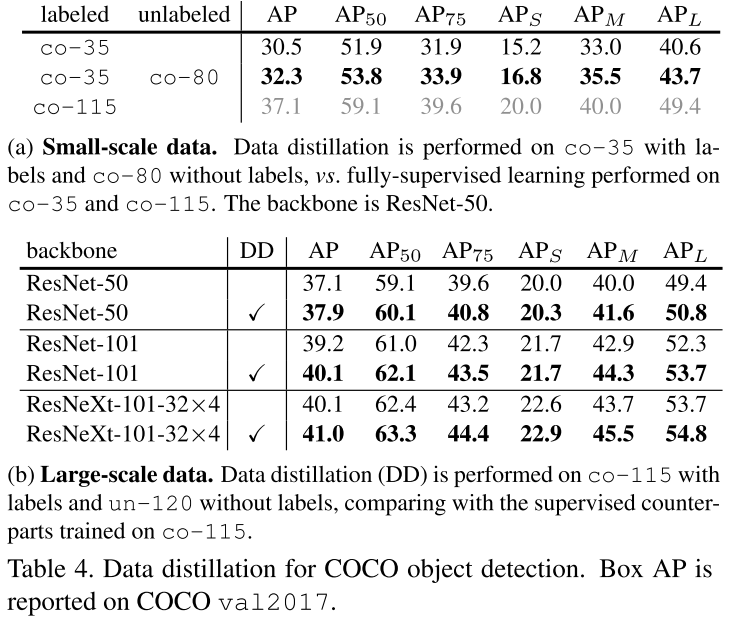
表4显示了结果:
1)小数据量:通过类似半监督的方法,将co-80作为无标记数据进行训练。
2)大数据量:co-115作为标记数据,un-120作为非标记数据
小数据量
co-35是下界,co-115是上界,我们发现DD方法更接近下界,这个问题在未来将进行更进一步的研究
大数据量
co-115是下界,应用DD之后数据都有不同的增长。
表4显示使用为标记的数据训练物体检测是一个更具挑战性的问题,但是DD策略仍然能够改进。