论文笔记 An Analysis of Scale Invariance in Object Detection - SNIP
Abstract
- 本文分析了各种用于识别和检测多样尺度物体的技术
- 对输入数据不同处理,比较特定尺度设计和尺度不变设计检测器
- 为了检验上采样对检测小物体是否必须,我们在ImageNet上评估了不同网络架构检测小目标的性能
- 基于此,我们提出一个深度端到端的可训练图像金字塔网络用于物体检测,其在训练和测试时使用相同图像尺寸
- 小物体和大物体分别在小尺寸和大尺寸图像想较难检测,我们提出一个新的训练架构:Scale Normalization for Image Pyramids,其选择不同尺寸物体实例的梯度反向传播,并视作图片尺寸的函数
- 单模型性能为45.7%,3网络组合mAP为48.3%,Imagenet-1000预训练,COCO数据仅使用bbox监督
- COCO 2017挑战 Best Student Entry
- Code
1. Introduction
图片分类任务:ImageNet-1000 top-5 error 2%
物体检测任务:COCO-80 mAP(0.5) 62%
为什么物体检测比图像分类困难这么多?因为尺寸多样性,特别是检测非常小的物体是非常困难的。
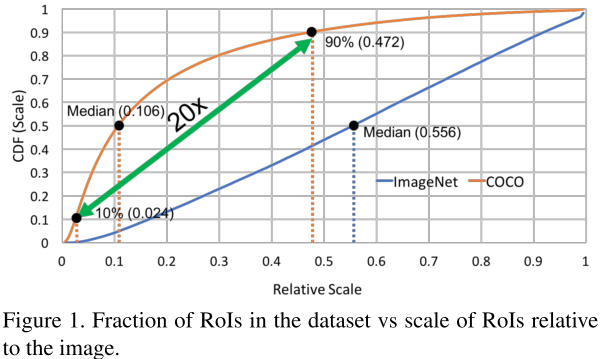
ImageNet的物体尺寸中位数的尺寸是图像的0.554,而COCO是0.106,即几乎一半的物体尺寸小于图像尺寸的10%,如图1所示。
这使得CNN必须能够处理尺寸多样性。并且由于分类和检测数据集的物体尺寸差异,导致在fine-tuning时会出现domain-shift问题。
本文,我们第一次展现了该问题的证据,并提出一种训练框架称为SNIP。
也有一些方法提出:
- 1)结合浅层和深层特征
- 2)使用膨胀或可变性卷积增加感知域用于检测大尺寸物体
- 3)在不同分辨率特征层分别预测不同尺寸的物体
- 4)结合语义进行检测
- 5)在各种尺寸上训练
- 6)在各种尺寸上测试,然后用NMS综合所有结果
上述结构创新显著改善了物体检测,但是有些训练问题没有讨论:
- 1)图像上采样是必须的么?为什么一般640x480的图像会上采样到800x1200?能否在预训练时就使用小stride?
- 2)从图像分类模型fine-tuning物体检测器,在图像缩放之后物体尺寸需要被固定么?或者需要覆盖所有的物体尺寸么?
Section3,研究输入不同尺寸图片对现有网络用于ImageNet分类的影响,修改CNN结构用于分布不同尺寸图像。实验表面上采样对检测小物体很重要
为了分析尺寸变化的影响,在Section5比较尺寸特定和尺寸不变设计检测器性能。
尺寸特定,对不同尺寸范围分别训练检测器,能够减少domain-shift影响,但是由于数据量减少对性能降低。尺度不变设计更加困难。
Section6,我们提出新的训练范式SNIP。通过图像金字塔实现尺度不变,选择合适的物体尺寸。为了减少主干CNN的域偏差,我们只反向传播与预训练模型具有相同分辨率的RoI或anchor。这样SNIP实现了所有物体均进行训练。
SNIP实际就是将ROI或anchor缩放到同一尺寸后进行训练,小物体放大,大物体缩小。
2. Related Work
3. 多尺度图像分布

本节研究域偏移的影响,我们研究这个问题因为先进检测器一般在在800x1200训练,1400x2000测试检测小物体
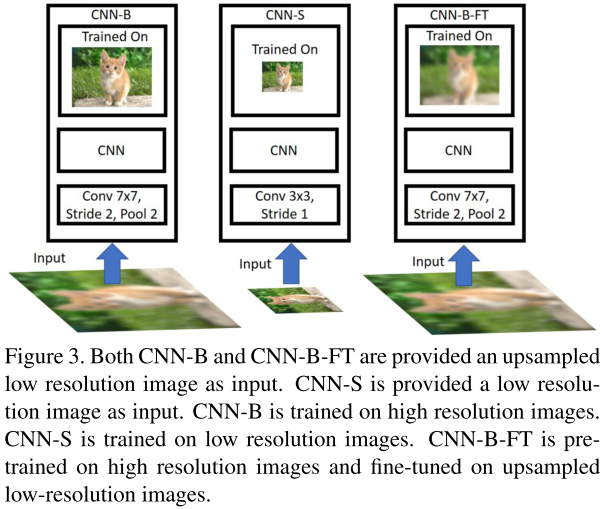
1)对ImageNet下采样到48,64,80,96,128,然后上采样到224进行训练,CNN-B(ResNet-101),结果如图3和图4(a)所示。随着训练和测试分辨率偏差的增大,性能逐步下降。
2)CNN-S 在48x48上训练并测试,将卷积核变为3x3,stride为1,在96x96上训练改为5x5,2。应用数据增强技术,随机裁剪,颜色增强。结果如图4所示。可以发现上述变化改进了小物体检测效果
3)CNN-B-FT,将下采样的图片上采样后进行训练,其效果优于CNN-S,说明在高分率图像上训练也能帮助在低分辨率图像上的识别。因此相比于减少stride,增大图像尺寸更好。
训练物体检测器可选择对不同分辨率训练不同检测器,或训练单一检测器,由于使用预训练的模型是很方便的,因此采用上采样图像并在高分辨率下预训练模型是更好的选择。目前主流的方法也是这一范式,我们的分析也支持这种选择。
4. 背景
介绍一些baseline方法,尤其是Deformable RFCN
5. 数据变换or正确尺寸?

GPU显存的限制,很多方法在低分辨率训练,高分辨率测试,这导致了第3节所说的尺度域偏移问题。不同设置训练检测器,在1400x2000上测试小物体检测(32x32以下物体)。结果如表1所示。
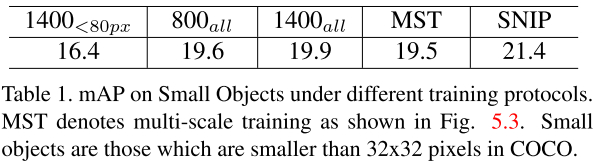
- 800all 图像分辨率为800x1200进行训练
- 1400all 缩放为1400x2000进行训练,提升有限,可能是大尺寸物体太多
- 800all<80px 仅使用低于80px的目标进行训练,但是结果发现性能变差,可能是减少了很多训练样本。
- MST,多尺寸训练,缩放图片,随机选择,效果仍然变成,可能是由于出现了极大或极小的物体。
因此我们认为,应在训练时选择合适的物体尺寸进行进行训练。
6. 图像金字塔上物体检测
目的是训练数据不仅包含最多样的外观和姿势,同时保证合适的尺寸约束。这种方法称为SNIP。并且我们还讨论了训练时GPU显存的限制。
6.1 SNIP
SNIP是MST的变种,其使得物体的分辨率接近预训练数据集。MST中大尺寸图像中的大目标和小尺寸图像的小目标不容易分类。为了避免这种情况,仅使用合适尺寸范围内的物体进行训练,其他的在反向传播时忽略。SNIP不仅减少了域偏差同时保存了所有多样的外观和姿势。表1显示SNIP对于小物体的有效性。
首先会排除掉尺寸不在范围之内的gt,然后anchor如果跟gt的iou大于0.3则也会被排除。测试阶段,对每个分辨率进行proposal和分类,如图6所示。并且不会选择分辨率在之外的检测结果。最后,缩放回正常尺寸,使用soft-NMS组合检测结果得到最后的结果。
ROI的分辨率在池化后接近预训练模型,使得模型更容易进行学习。对于位置感知的R-FCN等方法尤为重要。
6.2 采样子图
在高分辨率图像上训练深度网络需要更多的显存,因此我们裁剪图像来满足GPU显存限制,1000x1000能够覆盖图像中所有小物体。每张图随机生成50个1000x1000的chips,即crop images,然后选择覆盖物体最多的chips。这个过程不会影响训练结果。
7. 数据集和评估
COCO,123000图训练、验证,20288测试。由于COCO测试服务器没有召回率,我们使用118000训练,5000测试召回率。小物体面积为32x32以下,中物体32x32到96x96,大物体大于96x96。
7.1 训练细节
分别训练RPN和RCN,RPN训练6epochs,RCN训练7epochs。RCN使用OHEM,8个P6000 GPU,每个minibatch一种分辨率,因此一张图可能前向传播多次。如果没有正样本,当前图片被忽略。
尺寸范围:[0,80] at 1400x2000,[40,160] at 800x1200,[120,inf] at 480x800。
RPN在第一个epoch之后使用SNIP,RCN在第三个epochs之后,SNIP会增加一倍训练时间。
7.2 RPN细节
作者对RPN进行了一些改进
7.3 实验

表2显示了SNIP的提升相比MS和MST都是很明显的。
 表3显示了SNIP对RPN的改进,以及对不同尺寸物体的召回率
表3显示了SNIP对RPN的改进,以及对不同尺寸物体的召回率
 表4显示了SNIP对IPN(Image Pyramid Network)的影响
说明SNIP对RPN和分类均有作用
使用更好的主干网络能够获得更好的结果
全部使用DPN-92作为RPN,然后平均各网络的分类得分,得到的结果最优。
表4显示了SNIP对IPN(Image Pyramid Network)的影响
说明SNIP对RPN和分类均有作用
使用更好的主干网络能够获得更好的结果
全部使用DPN-92作为RPN,然后平均各网络的分类得分,得到的结果最优。