论文笔记《Rethinking Atrous Convolution for Semantic Image Segmentation》

Abstract
本文我们回顾了atrous 卷积,一个调整filter感知域并控制特征图分辨率的强大工具。为了处理多尺度目标分割,我们的模型使用不同空率(atrous rates)的atrous卷积进行级联或平行,以此来获得不同尺度的语义信息。并且,我们提出Atrous Spatial Pyramid Pooling (ASPP) 孔空间池化模型,探索多尺度上卷机特征具有图像级的全局特征编码并提升性能。本文提出的 DeepLabv3 比之前的版本提升,并且没有DenseCRF后处理,在VOC 2012图像分割benchmark上,实现与其他先进方法类似的性能。
1. Introduction
DCNN用于语义分割任务面临两个挑战:
- 池化和卷积步长会减小特征分辨率,妨碍需要丰富空间信息的任务,例如分割
- 目标的尺度多样性
解决方法:
- 使用 atrous 卷积 (也称为 膨胀(dilated) 卷积)来改变ImageNet预训练模型的功能,在网络的最后几层取消将采样操作,通过在filter的中间增加孔等同于提高卷积核尺寸。这样在不增加网络参数的情况下提升了特征图的分辨率。
- 图2显示了几种处理多尺度的方法:
- 图像金字塔
- 编码-解码,先提取特征,然后恢复空间分辨率
- 使用atrous级联获得高分辨率和大感知域特征
- 空间金字塔池化[^10][^80] 在特征图上使用不同比率的池化和filter操作得到不同的感受域
本文,我们使用atrous卷积增加感受域获得不同尺度的语义信息。我们提出的模型包含多种尺寸的atrous,并且发现batch normolization层对于训练很重要。我们发现使用3$\times$3的atrous卷积,如果空隙过大也不行,主要因为图像边界效应。ASPP中简单的退化为1$\times$1卷积来获得图像级的特征。后面我们会分享训练的经验机械,包括简单有效的bootstrapping方法来处理稀少和精细的标注目标。最后,我们的方法在PASCAL VOC 2012上实现了85.7%的精度,并不适用DenseCRF后处理。
2. Related Work

(a) 图像金字塔
(b) 编码-解码器
(c) 语义模型
(d) 空间金字塔池化
膨胀卷积 最近基于膨胀卷积的模型在语义分割领域很流行。[^73]研究了孔率(atrous rates)对获得大范围(long-rang)信息的影响。[^72]采用hyper孔率应用域ResNet最后两个Block。[^16]尝试学习可变形卷积。膨胀卷积也应用于目标检测[^56][^15][^31]
3. Methods
本节回顾了如何应用膨胀卷积提取高分辨率特征用于语义分割。后面讨论了,将膨胀卷积用于级联和平行模型中。
3.1 膨胀卷积用于Dense Feature 提取
DCNN由于池化和卷积步长导致特征分辨率降低。因此有些方法尝试用反卷积来恢复特征分辨率。但是,我们提倡使用膨胀卷积。膨胀卷积的公式如下:

- $x$ 输入特征
- $i$ 特征位置
- $r$ 孔率(atrous rates)
- $k$ filter尺寸
- $w$ 权重
膨胀卷积能够调整filter的感知域,如图1所示。因此,其能够让我们显式的控制全卷机网络中的特征响应尺寸。这里我们用output_stride 来表示输出的空间分辨率比例。假设一个DCNN的会缩小32倍,取消最后一个池化层或卷积层的步长设为1,然后后面的孔率设为2。这样在不增加任何参数的情况下提高特征分辨率。具体细节看[^10]
3.2 Going Deeper with Atrous Convolution
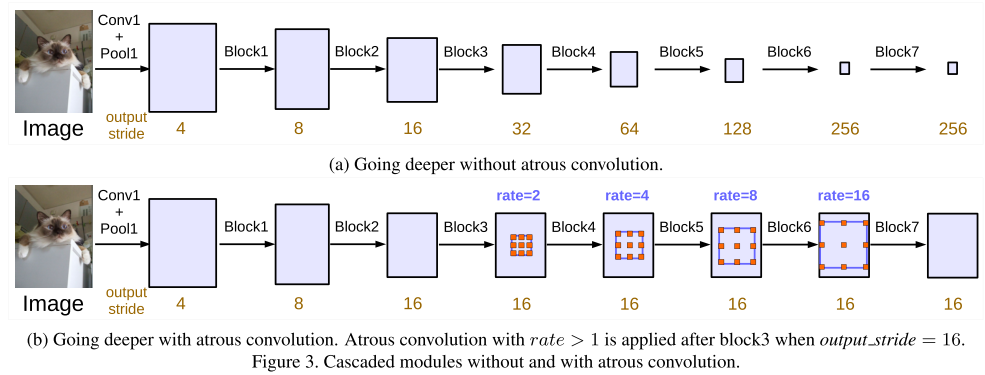
级联模型在ResNet的block4开始,使用atrous。本来使用stride和pooling是为了得到大范围的信息,最终缩小到低分辨率的特征图上。然而,我们发现,这样的stride丢失的信息会损害语义分割。因此采样atrous来保持分辨率。
3.2.1 多网格
受到之前一些研究对不同层级采用不同网格尺寸的启发,我们对block4到block7采用不同的孔率。$Multi\_Grid=(r_1,r_2,r_3)$ ,我们采用$rates=2\cdot(1,2,4)=(2,4,8)$。(这里不太懂是级联的用不同孔率,还是在一层上就用不同的空率)
3.3 Atrous Spatial Pyramid Pooling(ASPP)
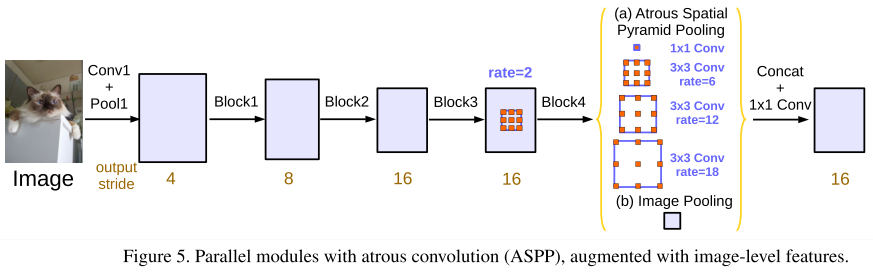
借鉴了SPP Net的平行空间分辨率的方法。这样能形成不同的感受域,更好的获得多尺度信息。但是,当孔率增加是,有效的filter权重数量也在变少(filter的权重用于特征区域,而不是padding)。当对一个65$\times$65的特征图应用不同孔率时,各个有效权重膨胀卷积操作的比例。当孔率增加,我们看到有效权重的数量减少,极端情况下,只有中心的fitler权重是有效权重。之后还有图像级池化。

4. Experimental Evaluation
网络模型使用ImageNet预训练的ResNet。在TensorFlow框架下实现。如果希望输出output _ stride=8,那就从block3开始用rate=2,block4的rate=4。
我们在PASCAL VOC 2012 语义分割benchmark上评估模型。评估指标为像素交并集。
4.1 训练方法
学习率 我们采用“poly”学习率,对初始学习率乘以$(1-\frac{iter}{max\_iter})^{power}$ ,$power=0.9$。
Crop Size 尺寸为512
Batch normolization 对ResNet增加模块全部包含batch normolization。后面这段是具体的训练细节。
Upsampling logits 对最后的结果进行上采样,来保证对原图进行反向传播,不损失原始的标注细节。
Data augmentation 对原图进行随机缩放(0.5~2.0),然后随机左右翻转。
4.2 使用膨胀卷积的深度网络
我们先实验了级联膨胀卷积的模型
ResNet-50: 表1,我们看见output _ stride影响,output _ stride的增加伴随着信号的损失,当采用膨胀卷积后,效果从20.29%提升到75.18%,说明膨胀卷积对级联block进行语义分割的重要性。

Res-50 vs. Res-101 两个网络模型,增加级联的block,其性能持续改善,但是提升逐渐减少。

Multigrid 表3显示了不同孔率搭配的结果。

Inference Strategy on val set 我们还尝试使用output _ stride=8的结果。然后对输入图像进行多尺度处理,左右翻转,也能进一步提升,最后的结果是对每个结果probability求平均。

4.3 ASPP
ASPP 表5我们实验了ASPP和应用于block4的Multigrid配合。应该是一个block中有多个卷积层,使用不同的rates,还有图像级的Image Pooling

Inference strategy on val set 同上。发现ASPP比级联的稍好。
与DeepLabv2比较 在没有DenseCRF和MS-COCO预训练的情况下已经比v2好。主要是改进因为fine-tuning batch normalization,以及更好的编码多尺度上下文。
Block5 + ASPP 我们尝试在组合级联和平行模型,在Block5上的效果却不好。
量化结果 在PASCAL VOC 2012测试集上的结果mIOU=85.7

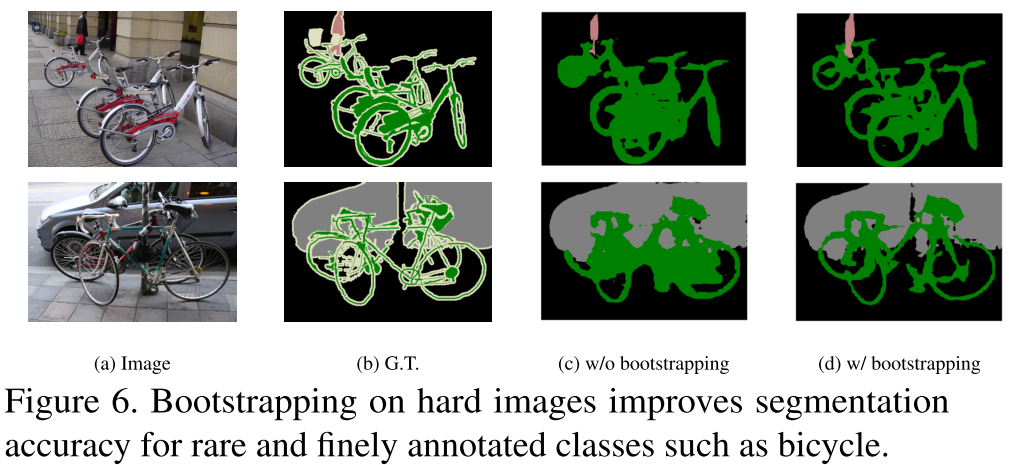
Bootstrapping 我们不是像其他人挖掘困难负样本,而是复制包含困难类别的图像。这样简单的Bootstrapping策略也能得到较好的结果。
1 | @article{Chen2017Rethinking, |
Reference
[^10]: L.-C. Chen, G. Papandreou, I.Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arXiv:1606.00915, 2016.
[^15]: J. Dai, Y. Li, K. He, and J. Sun. R-fcn: Object detection via region-based fully convolutional networks. arXiv:1605.06409, 2016.
[^16]: J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y.Wei. Deformable convolutional networks. arXiv:1703.06211, 2017.
[^31]: J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z.Wojna, Y. Song, S. Guadarrama, and K. Murphy. Speed/accuracy trade-offs for modern convolutional object detectors. In CVPR, 2017.
[^56]: G. Papandreou, I. Kokkinos, and P.-A. Savalle. Modeling local and global deformations in deep learning: Epitomic convolution, multiple instance learning, and sliding window detection. In CVPR, 2015.
[^72]: P.Wang, P. Chen, Y. Yuan, D. Liu, Z. Huang, X. Hou, and G. Cottrell. Understanding convolution for semantic segmen- tation. arXiv:1702.08502, 2017.
[^73]: Z. Wu, C. Shen, and A. van den Hengel. Bridging category-level and instance-level semantic image segmen- tation. arXiv:1605.06885, 2016.
[^80]: H. Zhao, J. Shi, X. Qi, X.Wang, and J. Jia. Pyramid scene parsing network. arXiv:1612.01105, 2016.