论文笔记《Is Faster R-CNN Doing Well for Pedestrian Detection?》
Abstract
行人检测是目标检测的特例。尽管近年Fast/Faster R-CNN在目标检测上效果显著,但是在行人检测上效果缺一般。之前的较好的行人检测算法一般是将手工特征和深度卷积特征相结合。本文,研究Faster R-CNN在行人检测上的问题。我们发现Faster R-CNN中的Region Proposal Network(RPN)区域推荐网络可以作为一个效果较好的独立的行人检测器,但是通过下游的检测器后其结果居然变差了。我们认为有两个原因:1)对于处理小目标,特征图的分辨率太小;2)缺少boostrapping策略来提取困难负样本。针对上述问题,我们提出使用RPN+boosted forests共享高分辨卷积特征图的方法。该方法的效果在多个benchmark上进行了评估(Caltech,INRIA,ETH,KITTI),其精度和速度均较好。
理解
本文提出了一种RPN+BF的行人检测方法,其创新性主要体现在:
- 使用卷积神经网络来进行区域推荐
- 使用卷积神经网络的特征图作为特征进行行人分类
- 证明了特征图的分辨率对行人检测的影响
- 证明了困难负样本的提取对检测率的提升的重要性
其本质上是利用了两个分类器,一个做区域推荐,其目的是高召回率,同时排除掉大部分的背景区域,另一个做精细的行人分类,把行人与非行人分类。这样做的好处是简化了两个分类器的任务,因为高检测率和低虚警是矛盾的,那么分为两个检测器后,就可以降低每个分类器的设计难度,同时使得后面那个分类器更加的专注,不用考虑特殊的背景干扰。
BibTex
1 | @inproceedings{Zhang2016a, |
1 Introduction
虽然近几年深度学习特征在计算机视觉的一些领域有重大突破,但是在行人识别中,手工特征仍然扮演着重要的角色。
**Faster R-CNN[^11]**在一般目标检测任务上效果较好,基于纯CNN模型,没有手工特征,其包含两个部分:
- 一个全卷机RPN,用于推荐候选区域
- 一个Fast R-CNN分类器
我们发现,PRN的行人检测效果,比后面加了Fast R-CNN的效果还好,可能有如下两个原因:
1)Fast R-CNN用于检测小目标的特征图太小
一般情况行人的尺寸是28x70 (caltech)。ROI的池化层(通常为16 pixel步长)导致低分辨率的特征图特征抹平。从而使得后面的分类器没有足够的特征进行分别。而一般手工特征得到的特征分辨率都较高。
我们解决的思路是在浅层池化而不是高分辨率层,然后通过hole algorithm(“` a trous”[^16] or filter rarefaction[^17] )来增加特征图的尺寸。
2)存在大量困难负样本
行人检测中困难负样本对行人检测的影响很大,这与目标检测中多类分类分问题不太一样。
为了解决这个问题我们采用**cascaded Boosted Forest (BF) [^18][^19]**,来提取困难负样本,然后对样本进行赋予权重。
与以前的方法采用手工特征训练BF不同,我们采用RPN的卷积特征训练BF,这样不仅能够节省计算时间,而且特征比手工特征更具表现力。
最后,我们的方法在多个数据集上进行了验证。特别的是,我们的方法对行人的定位更准,因为当IoU为0.7时,相比于其他方法有40%的提升。并且每个图像的处理时间是0.5s,与其他方法也较接近。
2 Related Work
集成通道特征Integrate Channel Feature(ICF)是从Viola Jones的框架扩展。ICF中涉及了金字塔和boosted分类器。ICF的改进版,如ACF,LDCF,SCF[^9],boosting算法仍然是行人检测中的关键基础。
由于R-CNN在目标检测领域的成果,目前有一系列方法采用两步法用于行人检测。
- 文献[^1]使用SCF做区域推荐+R-CNN分类器;
- TA-CNN使用ACF做区域推荐+R-CNN类方法,联合语义任务进行行人检测;
- DeepParts方法使用LDCF做区域推荐,然后使用神经网络做检测
可以发现,上述方法都是用一个单独的手工特征+boosted分类器作为区域提取。
- CompACT方法学习了一个手工特征和深度卷积特征结合的boosted分类器
- CCF是与我们方法最相似的一个,它是一个boosted分类器,使用深度卷积特征金字塔,但是没有区域推荐。
- 我们的方法没有金字塔,并且比CCF更快更精确。(用卷积特征)
3 Approach
我们的方法由两部分组成:
- RPN生成候选框和卷积特征图
- Boosted Forest作为分类器使用卷积特征
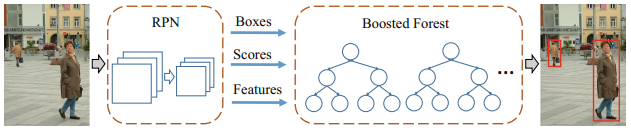
3.1 用于行人检测的区域推荐网络
Faster R-CNN的RPN主要是用于在多类目标检测场景中解决多类推荐问题。对于单一类别检测,RPN自然的可以只考虑一个类别。因此我们对RPN也进行了一定简化。
我们采用的参考框(anchors)是单一宽高比0.41(这个caltech里有统计过)。原始的RPN的宽高比是变化的。我们采用9个不同尺度的anchors,从40pixel高开始,1.3倍递增。因此我们不需要使用特征金字塔。
我们采用VGG-16预训练网络(ImageNet)作为主网络。RPN建立在Conv5_3之上,在他们之间有一个3x3卷积层和两个1x1卷积层用于分类和bounding box回归 **(more details in [11])**。 RPN的回归boxs具有16pixels的步长,分类层得到的置信度得分用于预测boxes,并且也作为Boosted Forest级联的初始化得分。
我们使用”a trous”技巧来提高分辨率,减少步长,但是RPN还是使用16 pixels步长,这个策略只用来提取特征,而不是用来fine-tuning。
3.2 特征提取
从RPN提取的区域,我们使用**RoI池化[^12]**提取固定长度的特征。不同于Faster R-CNN的fc层需要固定的特征纬度,BF没有这个限制。例如,面向Conv3_3,Conv4_3,提特征,虽然他们的特征图不一样,但是通过池化可以固定为7x7。不同层的特征可以简单的连接在一起,而深度分类器的特征归一化需要小心的处理。
由于BF对于特征纬度没有限制,因此我们可以增加特征的分辨率。原来RPN的各层的步长是(Conv3,步长4,Conv4,步长8,Conv5,步长16),我们使用”a trous”技巧得到更高的分辨率。例如,我们设pool3的步长是1,膨胀所有Conv4卷积2,Con4步长是4。不同于之前方法中会fine-tune膨胀之后的卷积核,我们的方法只是来提特征而不进行fine-tune。(这里好像有问题,你改变了卷积操作,而不fine-tune,那如何保证其效果比不fine-tune的效果好?有可能fine-tune之后RPN的整体效果下降了,但是可能提取高分辨特征的能力提升了)
我们的ROI分辨率于Faster R-CNN相同(7x7),但是特征图用的是更高的分辨率。如果输入的ROI尺寸小于7x7,池化会将特征抹平导致无法分别。
3.3 Boosted Forest
RPN网络产生推荐区域,置信度得分,特征,我们使用这些来训练级联Boosted Forest分类器。我们使用RealBoost算法[^18],超参采用借鉴[^4]。
- boostrap 训练6个stage,每次有{64,128,256,512,1024,1536}个树
- 开始训练样本包括,然后随机从推荐的区域中提取相同数量的负样本
- 经过每个stage训练后增加困难负样本(正样本数量的10%)
- 最后通过所有stage得到一个2048个树的森林
- 实现是在pdollar的工具包基础上
RPN类似一个stage-0的分类器,通过它我们可以得推荐区域的置信度得分s,我们令$f_0=\frac{1}{2} log\frac{s}{1-s}$,后面接RealBoost分类器。其他的阶段就是标准的RealBoost。
3.4 实现细节
- 我们采用单一尺度进行训练和测试
- 检测框与GT的IoU超过0.5则认为是检测到
- 采用image-centric训练框架[^11][^12]
- 每个mini-batch包含1个图像和120个随机矩形框,正负样本比为1:5
- RPN的超参采用文献[^11]采用的
- 我们发现[^11]在fine-tune中不使用边界交叉的矩形框,但是我们保留下来能提供精度
- 推荐区域NMS的阈值为0.7
- 推荐区域按得分排序,每个图片只取前1000个区域
- 树的深度对Caltech和KITTI是5,对INRIA和ETH是2
- 测试的时候我们RPN的前100个区域给BF进行分类
4 实验和分析
4.1 数据集
- 我们在四个数据集上机械能了测试,Caltech、INRIA、ETH、KITTI。IoU设为0.5。
- Caltech数据集,其中有4024个图像是用于测试,测试标准为50 pixel高,65%可见。
- INRIA和ETH用于验证模型的泛化能力。
- KITTI包含立体数据,我们用左相机的7481个图像进行训练
4.2 实验
这个部分主要在Caltech数据集上进行。
RPN对行人检测足够好么?
我们测试了RPN在不同IoU和不同区域1、4、100数量时的召回率。如图所示,可以发现RPN相比于传统特征ACF、LDCF、Checkerboards的效果较好。100个推荐区域在IoU=0.7时的召回率大于95%。

RPN单独作为行人检测器时,MR为14.9%。
特征分辨率的影响
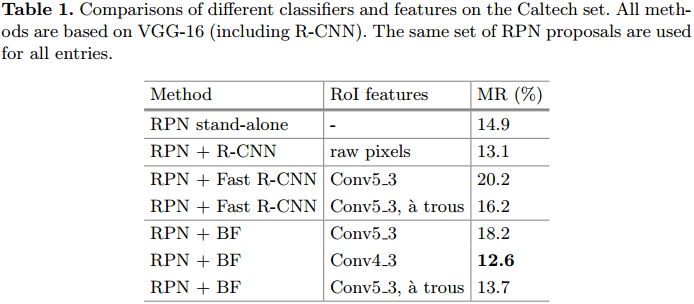
- RPN + R-CNN的效果比RPN好,R-CNN使用的是原始的像素信息,因此特征分辨率的影响较小。
- RPN + Fast R-CNN的效果就变差了,但是通过a trous技巧提升分辨率后,MR就减小了
- RPN + BF,特征图的分辨率与MR有直接关系
如果我们确定了RPN + BF的框架,那么应该选择哪些卷积层特征呢?作者做了比较。
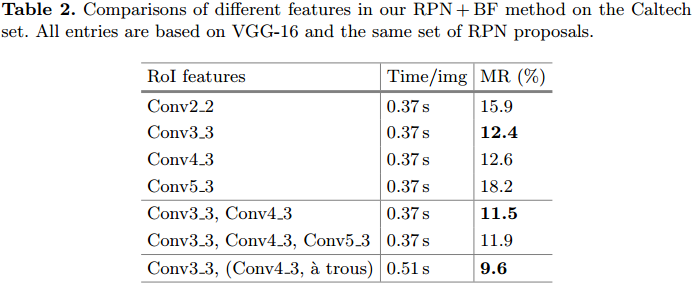
从表2可知,分辨率可以降低MR,但是卷积层的增加可以提供特征描述能力,最好发现Conv3_3和Conv4_3(a trous)的效果最好。并且计算效率也比较高。Tesla K40 GPU平台,0.5s处理一张图像。

Bootstrapping重要么?

从上图中可以发现,使用了bootstrapping之后的效果会提升,而且采用Fast R-CNN和BF的差别不大,可以认为bootstrapping对检测率的提升很重要。
4.3 与目前先进的方法比较
这里作者在各种数据集上和很多检测器的效果进行了比较,总之就是各种好。
5 结论和讨论
我们提出了一组非常有效的的行人检测方法,基于RPN和BF。PRN用于区域推荐和计算特征,BF分类器更加灵活:1)结合不同卷积层的不同分辨率的特征。2)配合bootstrapping进行困难负样本提取。这两个特征有效克服了Faster R-CNN对行人检测的限制。
我们发现有趣的是bootstrapping是一个非常关键的组件,甚至对深度神经网络也是。目前已经有人开展这方面的工作,称作**Online Hard Example Mining(OHEM)[^32]**来训练Fast R-CNN用于目标检测。比较端到端的在线挖掘方法和多阶段的级联bootstrapping方法是一个非常有趣的方向。
Reference
[^1]: Hosang, J., Omran, M., Benenson, R., Schiele, B.: Taking a deeper look at pedestrians. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015)
[^4]: Cai, Z., Saberian, M., Vasconcelos, N.: Learning complexity-aware cascades for deep pedestrian detection. In: IEEE International Conference on Computer Vision (ICCV) (2015)
[^9]: Benenson, R., Omran, M., Hosang, J., Schiele, B.: Ten years of pedestrian detection, what have we learned? In: Agapito, L., Bronstein, M.M., Rother, C. (eds.) ECCV 2014 Workshops. LNCS, vol. 8926, pp. 613–627. Springer, Heidelberg (2015)
[^11]: Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. In: Neural Information Processing Systems (NIPS) (2015)
[^12]: Girshick, R.: Fast R-CNN. In: IEEE International Conference on Computer Vision (ICCV) (2015)
[^16]: Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation with deep convolutional nets, fully connected CRFs (2014). arXiv :1412.7062
[^17]: Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015)
[^18]: Friedman, J., Hastie, T., Tibshirani, R., et al.: Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 28, 337–407 (2000)
[^19]: Appel, R., Fuchs, T., Doll´ ar, P., Perona, P.: Quickly boosting decision trees-pruning underachieving features early. In: International Conference on Machine Learning (ICML) (2013)
[^32]: Shrivastava, A., Gupta, A., Girshick, R.: Training region-based object detectors with online hard example mining (2016). arXiv:1604.03540