论文笔记《DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling》
Abstract
- ICCV2017
- code
- ROI Sparse Sampling
1. Introduction
1.2 Probabilistic Object Detection
- 一个BBox只能对应一个类别的一个实例
- 因为没有前置过滤,所以存在大量的候选ROI
- 所以将采样是目前可行的方法
- YOLO和Faster R-CNN采样数量在$10^4$ 到$10^5$,然后通过简单的线性回归精细化BBox位置
- 我们认为目标实例是大规模采样的一个非常小的子集
- 基于此,我们开发端到端的CNN来估计该稀疏分布
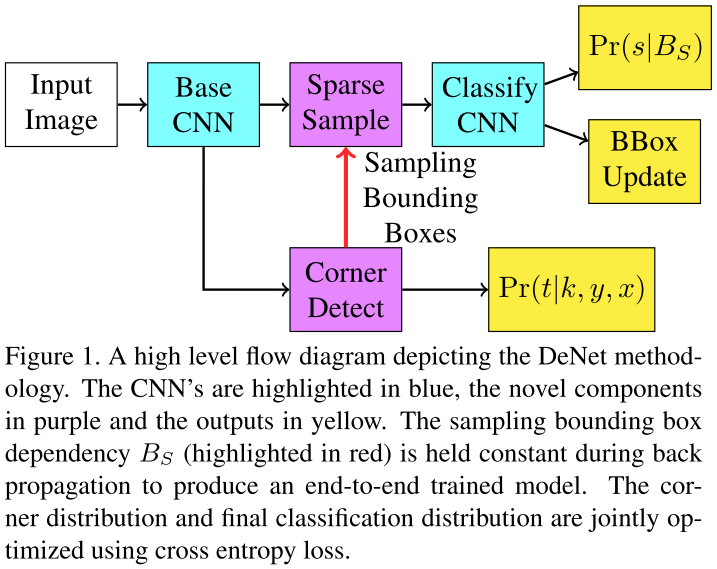
2. Dirested Sparse Sampling (DSS)
- DSS用于联合优化two stage CNN
2.1 Corner-based RoI Detector
- 提出一个概念:BBox角估计用于ROI估计
- 估计图像上每个位置是否是BBox的一个角 $Pr(t|k,y,x)$
- $k \in { top
left,topright,bottomleft,bottomright }$ 一个角类型 - 一个BBox包含物体的似然估计 $Pr(s\neq null|B)\propto \prod_{k} Pt(t|k,y_k,x_k)$ 即BBox四个角的概率的乘积
2.2 训练
- 先前向传播获得$B_s$
- 并且随机采样Ground Truth增强$B_s$
- 然后通过后续的分类网络训练
- 为了保证端到端训练,$B_s$不变
- 因此corner检测网络在bbox分类和估计任务中联合训练
- DeNet模型在corner概率分布,分类分布,bbox回归上进行联合优化
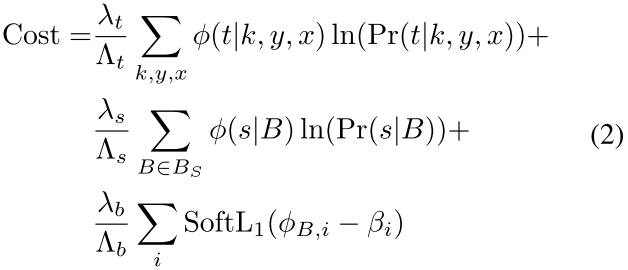
- $\phi$ 是ground truth corner 和 classification 分布
- $\phi_{B,i}={x_i,y_i,w_i,h_i}$ 是ground truth 与 bbox中IoU最大的box
- $\lambda_s,\lambda_t,\lambda_b$ 是用户定义的常数
- $\Lambda_s,\Lambda_t,\Lambda_b$ 是归一化常数,使得每个部件为1
- $\phi(t|k,y,x)$ 是遍历ground truth后得到的corner map,超出边界的corner则丢弃
- $\phi(s,B)$ 是预先遍历的采样bbox和ground truth的分类结果
2.3 Detection Model
- Residual neural networks 比 Faster R-CNN 展现出更好的性能
- 我们选择34层,ResNet-34作为我们的base网络,参数21M
- 对基本模型,输入图像均归一化为512$\times$512,去除最后的平均池化和全连接层,并连接两个反卷积层和一个corner detector
- corner detector负责生成corner分布,并通过每个位置的特征$F_s$得到特征采样图
- 反卷积层增加特征图的分辨率
- corner detector之后是sparse layer,其观察corner标识符,生成采样ROIs
- ROIs用于提取一组N$\times$N的特征向量,从特征采样图中
- 至此,我们从4.2M个bbox中稀疏采样了$N^2$个bbox
- 特征向量包括最近近邻的采样特征,一个7$\times$7的网格加上bbox的宽高。$7 \times 7\times F_s + 2$
- 近邻采样是足够的,特征采样图具有相似,高度相关,稀疏分辨率
- 最后特征向量通过一个相对浅全连接网络生成最后的分类结果和细调边界的ROI


表1和表2描述了增加的网络信息,相关定义如下:
- Conv 参数使用正态分布,$\sigma^2=2/(n_fn_xn_y)$,之后是batch normalization和ReLU激活函数
- Deconv ReLU之后是反卷积,其等价于先扩大空间分辨率再进行卷积
- Corner 通过soft-max函数估计corner分布,并生成采样特征图
- Sparse bbox采样标识符,从corner分布,并生成一个固定尺寸的采用特征,从采用特征图
- Classifier 特征图到概率分布,通过softmax函数,并生成bbox
对于DeNet-34我们使用ResNet-34作为base model,$F_s = 96$ 用于产生特征向量4706个值,32M个参数。DeNet-101模型使用ResNet-101 base model 增加的filter数量大约是1.5$\times$。
2.3.1 Skip Layer Variant
skip层连接反卷积层和最后的输出层,使其具有相同的空间维度。每一个skip layer将原特征线性投影到目标特征维度,并简单的增加激活层之前的特征图。
2.3.2 Wide Variant
通过增加翻卷机和skip层,使得corner和feature sampling map的空间分辨率为128$\times$128。同时N增加到48,产生2304个ROI。虽然目前的版本由于增加了分类步骤使得计算开销增加,但是通过工程方法,作者相信可以减少计算开销。
3. 实现细节
代码基于Theano,下载地址:https://github.com/lachlants/denet
3.1 训练方法
使用Nesterov风格的SGD,初始lr=0.1,动量=0.9,权重衰减=0.0001。一个batch=128,32个样本。epoch=30,60时,lr除以10,一共90个epoch。其他的超参与原始的residual network一样。没有使用在线困难负样本挖掘或其他梯度优化技术,增加10%的负样本在训练阶段。
为了改进模型对不同尺度的泛化性,对每个样本,生成一个最小的边框得到一个方形图像。在测试时,使用双线性差值得到512$\times$512的图像,在训练时随机crop一个0.08~1.0相对大小的图像,宽高比(3/4,4/3)。如果该crop图像没有包含50%的GT,则再生成一个。如同测试一样所有crop都缩放到512$\times$512。并且也使用随机光度调整和镜像调整(对比、饱和、明亮)[^20]。
3.2 定义采样BBox
一个简单的方法快速搜索corner分布
- 搜索$Pr(t=1|k,y,x)>\lambda$的点$C_\lambda$
- 对每个corner类型,选择M个具有最大似然的corners $C_M \subseteq C_\lambda$
- 生成一组唯一的bbox,通过用$C_M$中每个左上匹配每个右下corner
- 计算每个bbox的概率
- 重复步骤2和3用右上和左下
- 对bbox的概率排序,保留前$N^2$产生采样bbox$B_S$
此方法在步骤1过滤了绝大部分corner,因此相比暴力穷举能加速。
4. 结果和分析
模型比较是困难的,因为使用了不同的base model,数据增强策略,数据集融合。特别的,我们注意到SSD使用更大的batch size,而R-CNN使用更大的输入分辨率。我们的DeNet使用一个Titan X GPU 进行训练,8x 的 batch size与SSD设置一样。为了简洁,我们只包含三种Faster R-CNN模型,RPN(VGG),ResNet-101 extension RPN+,R-FCN。
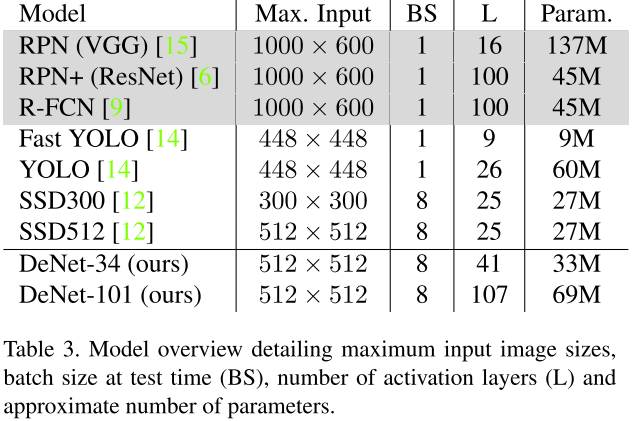
表3提供了baseline模型的总体情况。


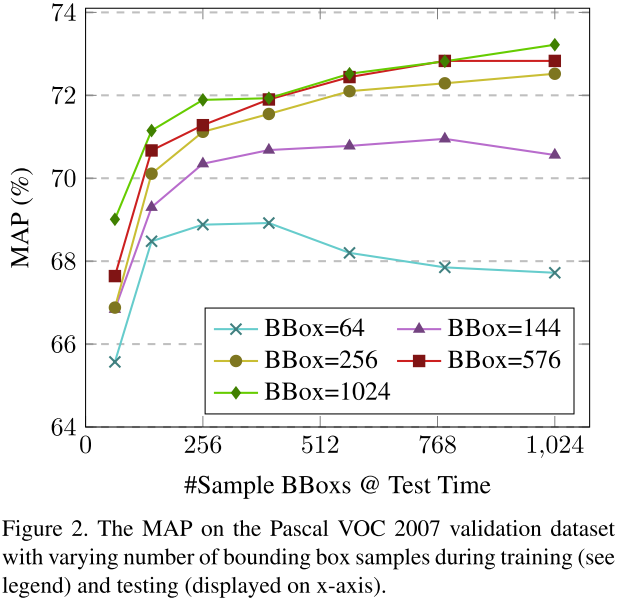
4.1 超参优化
我们使用3.1节使用的训练策略,除了batch使用96。Denet-34模型在07的train和12的trainval上训练,测试在07的val上测试。
表4为粗略搜索corner和bbox回归损失参数。当$\lambda_s=1,\lambda_t=100,\lambda_b=1$时得到的最优的结果。之后我们研究了bbox采样数量的影响,我们设置模型训练的采样数量N={8,12,16,24,32}(注意:采样数量是N的平方)。在测试阶段,我们变化N的值从8到32生成图2。表5中,我们提供了采样bbox数量和检测速率、coverage覆盖率(就是召回率)的关系,如同第二节上的描述。很明显,虽则采样bbox的增加,MAP持续改进。同时,增加测试的bbox,也会改进MAP,但是会降低检测率。在之后的实验中,我们设置N=24用于训练和测试。
4.2 效率分析
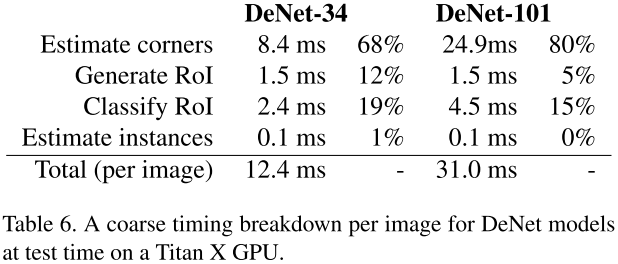
表6展示了DeNet模型不同模块的消耗时间,我们将运行时间分为4个stage
- corners估计,图像上传到GPU,通过网络后生成corner分布和采样特征图,corner分布之后从GPU迁移到CPU
- 生成ROI,根据corner分布,生成采样bbox
- 分类ROI,最后分类CNN执行,分类分布到bbox回归输出,从GPU到CPU
- 实例估计,在检测结果上进行NMS
我们发现大部分时间都消耗在生成corners,cpu生成ROI也需要许多时间。但是DeNet还是比大部分其他baseline方法快。
- 反卷积,通过反卷积层增加空间信息,不同于R-FCN和SSD方法。这种方法在后面进行,能极大的改进评估效率。
- 快速ROI特征,通过简单的最近邻采样方法提取特征,限制特征的数量为每ROI有49个。有个RPN变体使用49~580
- 输入图像纬度,DeNet将所有图像缩放到512$\times$512,而一些RPN方法会将输入变为1000$\times$600
- Batching,我们的模型8x采样每batch,改进GPU的利用。
4.3 ROI召回率比较
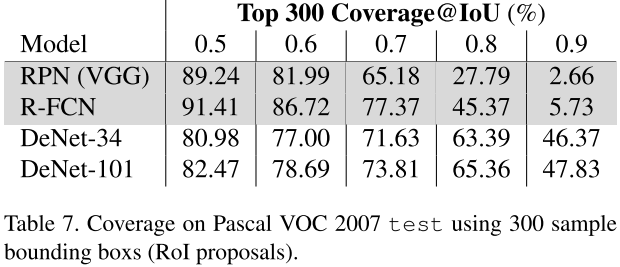
表7显示了300个ROI的情况下的召回率。我们发现在IoU较低的时候RPN和R-FCN的召回率更好,但是增加IoU后DeNet极大的改进了召回率。
我们发现RPN/R-FCN利用了bbox回归和nms方法,在推荐网络中。DeNet的ROI召回率不意味着完整模型的MAP。
4.4 MSCOCO
微软的COCO数据集包含82K的训练和40K的验证图像,包含80个类别。对于测试他们数据集包含80K的测试集,用户已知20K的测试test-dev2015,和未知的20K图像test2015只允许5次评估。由于数据集体积、类别的数量、目标相对大小,MSCOCO相比于Pascal VOC更具挑战性。COCO的评估方法是MAP,在IOU=0.5到0.95。该评估策略更加注重定位性能。设置$\lambda_t=50$是DeNet-101收敛必要的。DeNet-34训练4天,2个Tesla P100 GPU;DeNet-101需要6.5天,4个Tesla P100GPU。
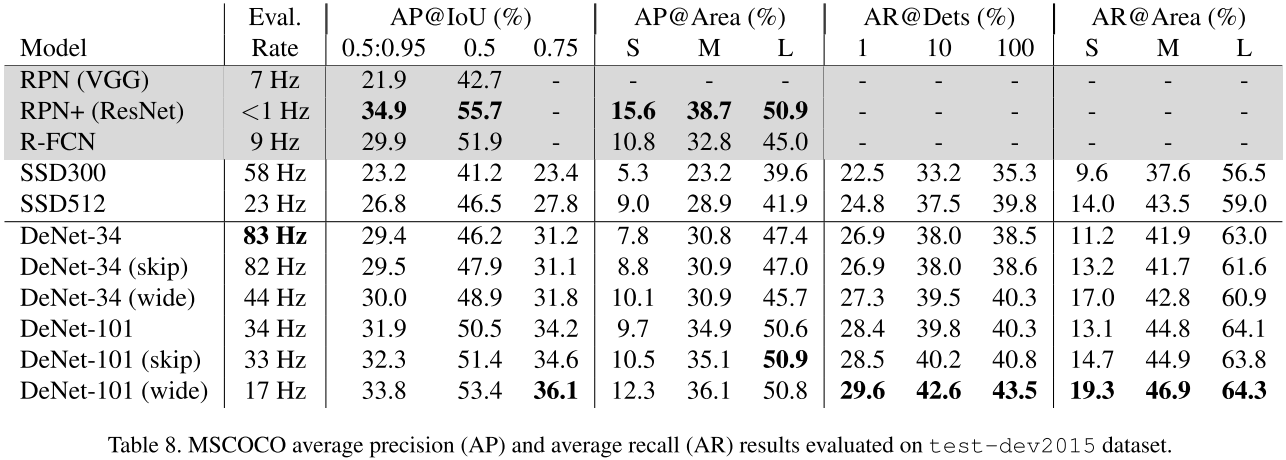
表8显示了在COCO test-dev2015上的效果,DeNet展现出高献策速度上的优势,相比SSD300,MAP提升6.2%,比SSD512提升2.6%。DeNet-101的优势也很明显, 只是被RPN+击败。文章撰写时,DeNet在COCO上排名前10,其不考虑计算效率。skip 模型变体继续改进中小目标的性能。wide 模型变体改进小目标和定位性能。DeNet在更多的候选ROI上进行选择,相比SSD。RPN和YOLO等方法是不可能使用如此大的候选ROI。
4.5 Pascal VOC 2007

表9现在了在Pascal上的测试,训练集用07+12的trainval,测试集用07。DeNet-34训练13小时,DeNet-101训练20小时。DeNet-34 skip版本比SSD300的MAP提升1.6%,速度快20Hz。DeNet-101性能匹配SSD512,速度更快。
4.6 Pascal VOC 2012
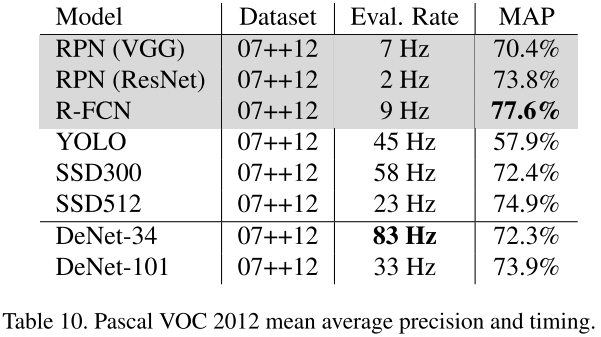
训练集为07的trainvaltest+12的trainval,测试集为12的testing server。我们可以发现DeNet-34性能匹配SSD300,但是不知道什么原因,DeNet-101性能低于SSD512,并且性能接近RPN+。训练时间分别为18小时,28小时。
5. 总结
本文提供了一个基于CNN的稀疏框架,包含ROI检测器和分类模型,通过减少手工优化得到先进的性能和实时效率。通过反卷积和skip层,我们得到更高的计算效率模型通过更耦合ROI、分类、bbox回归。我们的实验表面,skip连接能改进中小目标的检测性能。wide模型表面corner图的分辨对于中小目标的重要性,其提供了未来的研究方向。
通过分析发现,我们的模型定位性能更好。我们认为是由于我们的采样候选ROI更多(4.2$\times 10^6$)而SSD512和RPN是(2.5$\times 10^4$) 。这使得模型可能选择一个更加接近gt的bbox。另外,由于我们不再设定一组reference bbox,因此减少了手工调整的需要(就是anchor设置)。这样就不存在匹配各种各样目标尺寸和分辨率的问题。
分析
本文的corner map是该文章的亮点,相当于网络进行了一次bbox的位置粗略估计,其本质上跟rpn没有区别,但是却能得到更快的效率,其原因是bbox的粗略估计是非常快的,然后就马上进行了一次预筛选。而RPN等方法需要将anchor完整计算一遍因此效率更慢,corner map是一次计算得到,之后的bbox生成不再需要神经网络。而RPN需要对每个位置进行全连接网络的计算,因此速度较慢。